Context Windows Explained: The Math, Limits, and Future of AI Memory
Why AI's ability to "remember" is bounded by math—and what comes next
Introduction
The growth of Large Language Models (LLMs) has been defined as much by their memory as by their intelligence. When OpenAI extended GPT-4 Turbo to a 128K context window, and Anthropic announced Claude with 200K tokens, it sounded like a breakthrough: suddenly, these models could "read" hundreds of pages at once. Google's Gemini 1.5 went further, claiming support for 1M tokens.
How Context Windows Work: The Math Behind Token Attention
At the core of transformers lies the attention mechanism, which lets each token decide which prior tokens to focus on. The process: Inputs (words, symbols, numbers) are broken into tokens. Each token generates three vectors: Query (Q): "What am I looking for?", Key (K): "What do I represent?", Value (V): "What information do I carry?"
The Fundamental Equation
- QK^T: similarity score between tokens
- √d_k: scaling factor
- Softmax: probability distribution across all prior tokens
This design means every token compares itself to all other tokens. That's powerful—but also computationally expensive.
Why Context Windows Hit Scaling Limits
The attention matrix is quadratic: For n tokens, attention requires n × n operations. Complexity grows as O(n²).
Implications
- GPU Memory: Each attention matrix must fit in VRAM
- Latency: Training and inference slow dramatically with longer sequences
- Noise: The longer the input, the harder it is for relevant tokens to stand out
That's why models cap context windows—even if you can technically extend them, the signal-to-noise ratio collapses.
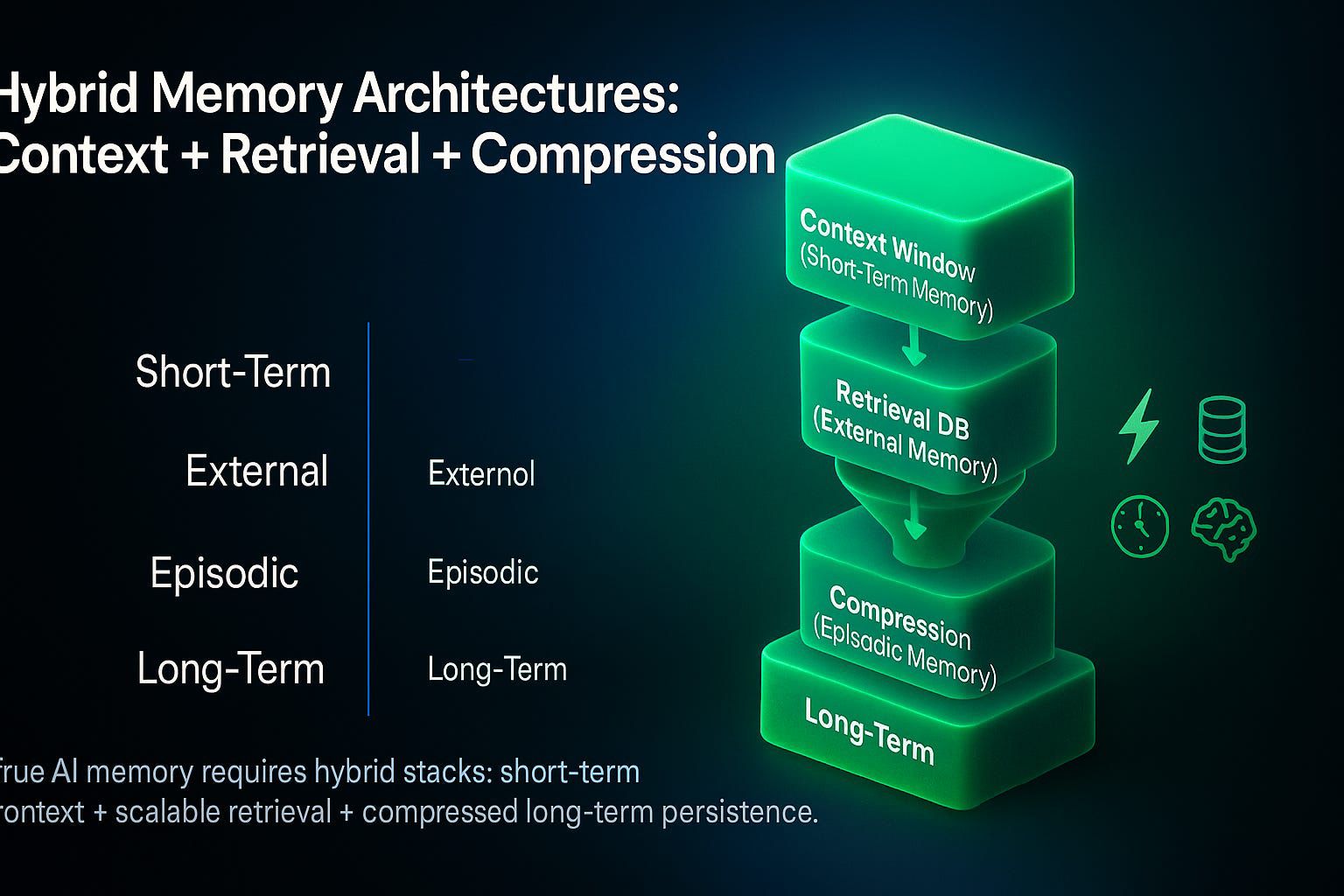
Beyond Context Windows: Hybrid Memory Architectures
The future lies in hybrid memory stacks, not brute force context. Four layers of memory:
Context Window (Short-Term Memory)
Immediate active tokens
Retrieval DB (External Memory)
Vector database that fetches only what matters
Compression Layer (Episodic Memory)
Summaries of past interactions
Persistent Memory (Long-Term)
Knowledge retained across sessions
Why It Matters
- Keeps compute costs bounded
- Improves accuracy by filtering noise
- Enables agent-like continuity across conversations
This is where retrieval-augmented generation (RAG) and episodic storage converge—creating AI systems that remember without exploding compute budgets.
Closing Thought
The race for ever-larger context windows will continue—but it's not where the real breakthrough lies. The next frontier is hybrid AI memory: architectures that blend short-term context, retrieval databases, episodic compression, and long-term persistence.
For AI leaders, this means shifting the focus from "How big is the context window?" to "How efficiently does the system use memory?"
That is the real step from language models to reasoning agents.